这两天把编译原理词法分析实验提前给做了,作品地址:http://115.159.147.250:666/Lexical/,源码:https://github.com/netcan/compilingTheory,效果图:
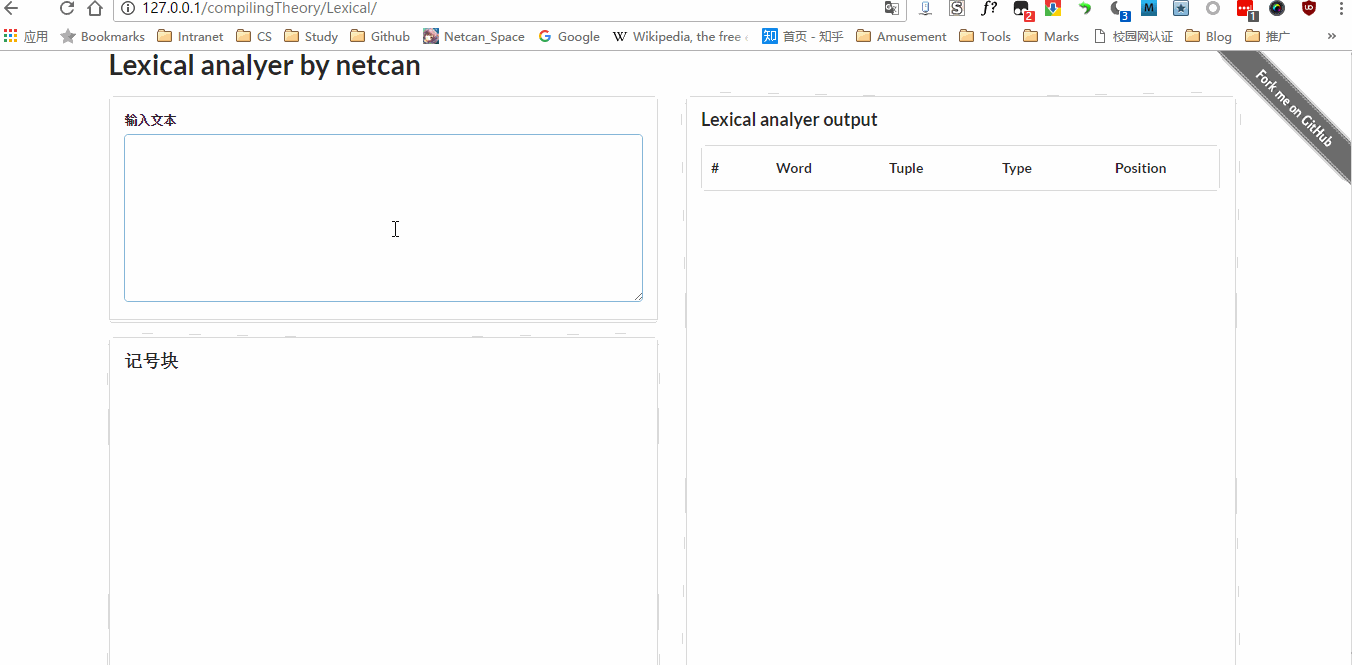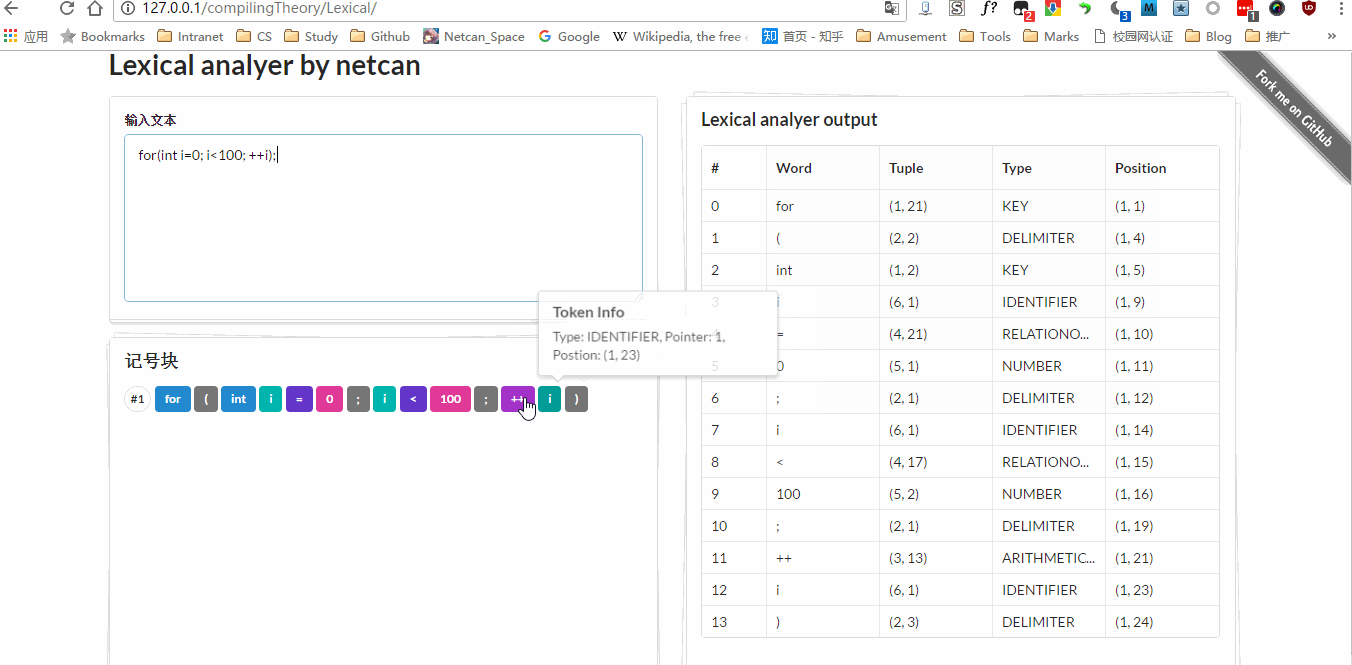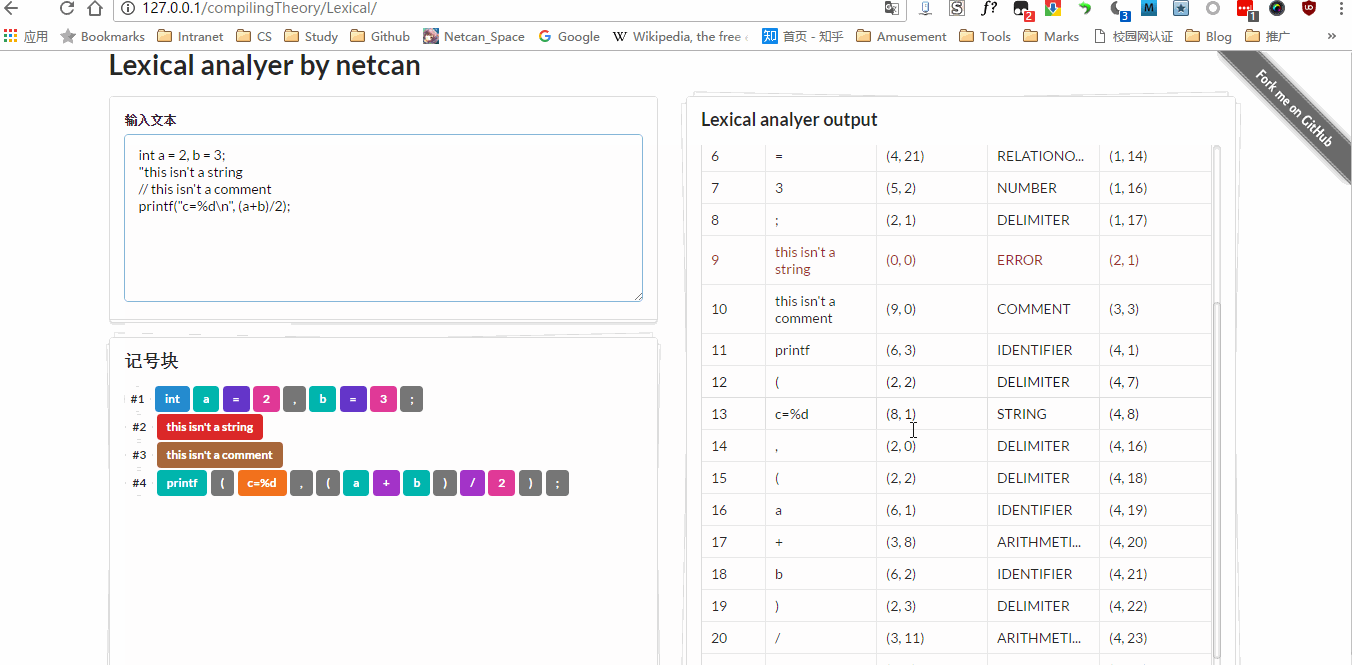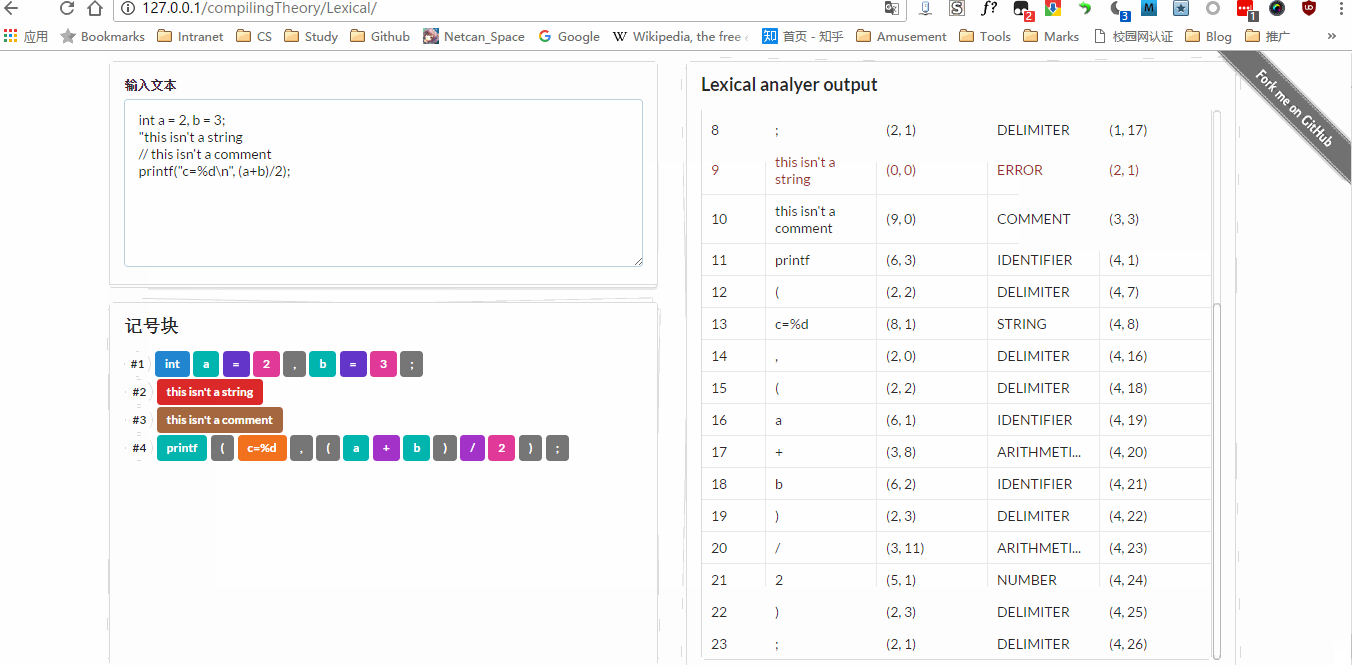
现在来记录下编写心得,这是编译原理的第一个实验,算是热身实验吧,确实很简单,花了一晚上就把词法分析器底层部分写完了,老师比较喜欢图形界面,后来又加了前端,也就是现在看到的效果。实验要求能够匹配出 关键字 、 标记符 、 运算符 、 分界符 、 无符号数 ,后来我又添加了一部分,现在能匹配出 字符 / 字符串 、 行间注释。
词法分析器底层部分
底层部分是用 C++ 写的,大体思路就是,每次从 stdin 读取出一行,然后从这行的第一个字符开始匹配。匹配完了,读取下一行,行号 +1。
匹配 关键字 或标记符 自动机
若当前匹配到的字符 Pointer。最后输出相关信息。
匹配 无符号数 自动机
若当前匹配到的字符 Pointer,若不是 无符号数 则当 错误 处理。最后输出相关信息。
匹配 行间注释 自动机
若当前匹配到的字符
匹配 运算符 、 分界符 自动机
我将 运算符 和分界符 放到一个 optrs 表中,若当前匹配到的字符 optrs的元素,就继续匹配下一个字符,直到下个字符 optrs 的元素或者运算符类型与字符 optrs 的元素,并确定其类型,其 Pointer 为该 运算符 或分界符 在optrs的位置,输出相关信息,否则当 错误 处理。最后输出相关信息。
匹配 字符 、 字符串 自动机
若当前匹配到的字符 "或者 ',就继续匹配下一个字符,直到下个字符Pointer,若不符合则 错误 处理。最后输出相关信息。
词法分析器前端部分
前端部分我比较认真,我用 html+js+php 来实现图形界面,之所以写成网页,是因为我不想写 native app,我也没GUI 开发环境。在互联网时代,webapp是趋势,谁还写本地客户端啊,况且带个几十 M 的 GUI 库实在是麻烦。
于是我的分析器底层部分设计成输出 json 格式,然后利用管道将 C++ 程序与 php 程序进行数据传送。前端只要用 js 输数据取数据渲染页面即可。
在这之中发现一个问题,如果 输入文本 一长,渲染效率大大降低,因为我用 append 方法一个个加元素的。解决方案是最后转换为字符串一次性输出渲染,效率提高了不少。具体可看这个优化片段:优化 js 运行效率。

