编译原理第二个实验是 LL(1)语法分析,这里我来写一下关于 LL(1)的内容,虽然书上都有,但是总结一遍,应该印象更加深刻的,也有助于写代码。目前 LL(1)实验已全部完成,项目地址:http://115.159.147.250:666/LL1/,代码地址:https://github.com/netcan/compilingTheory,效果图:
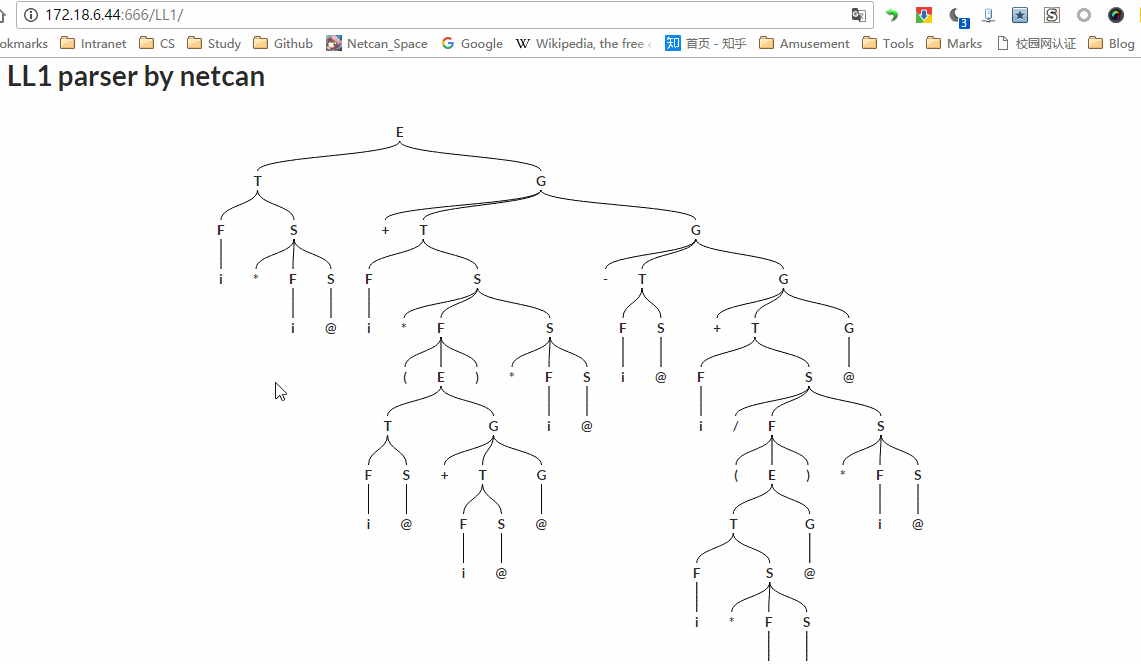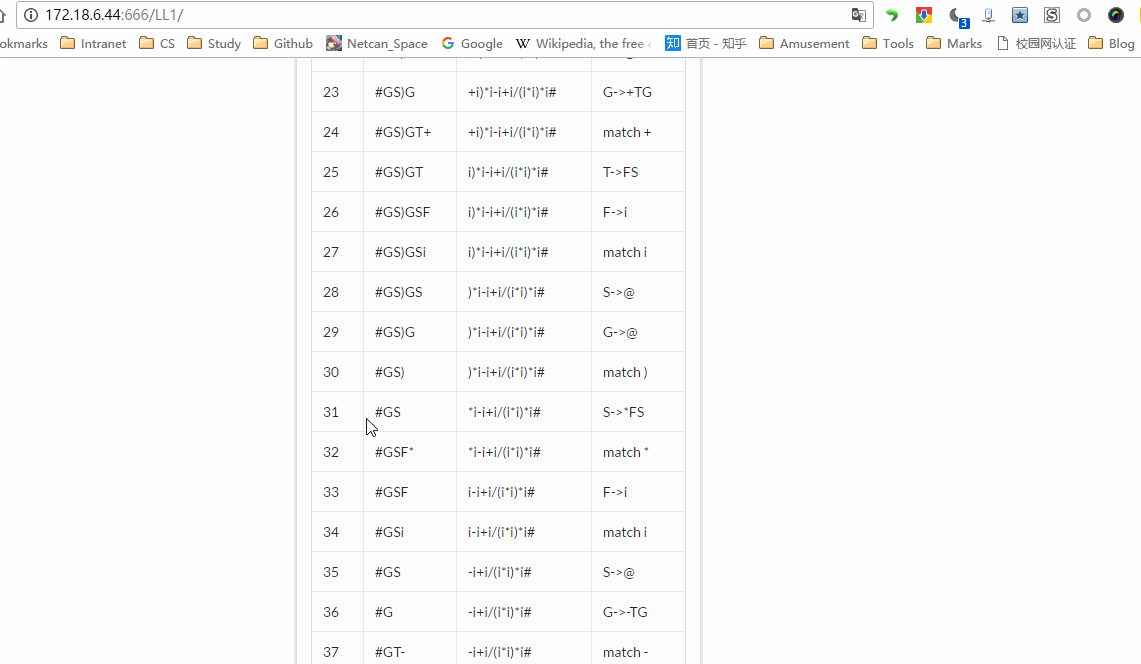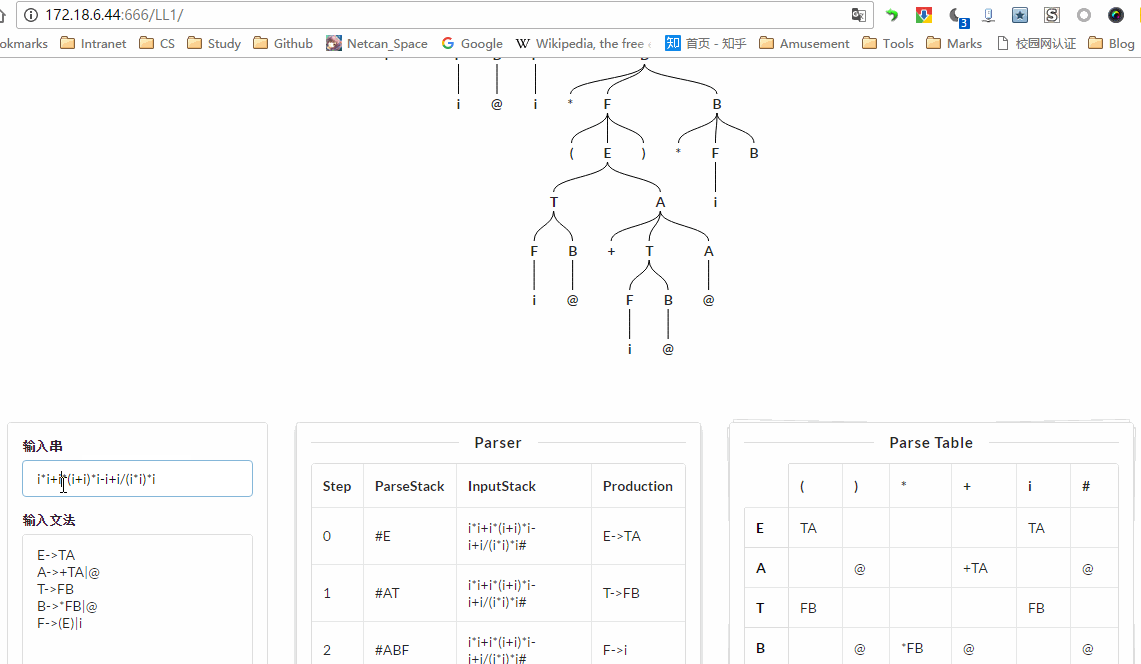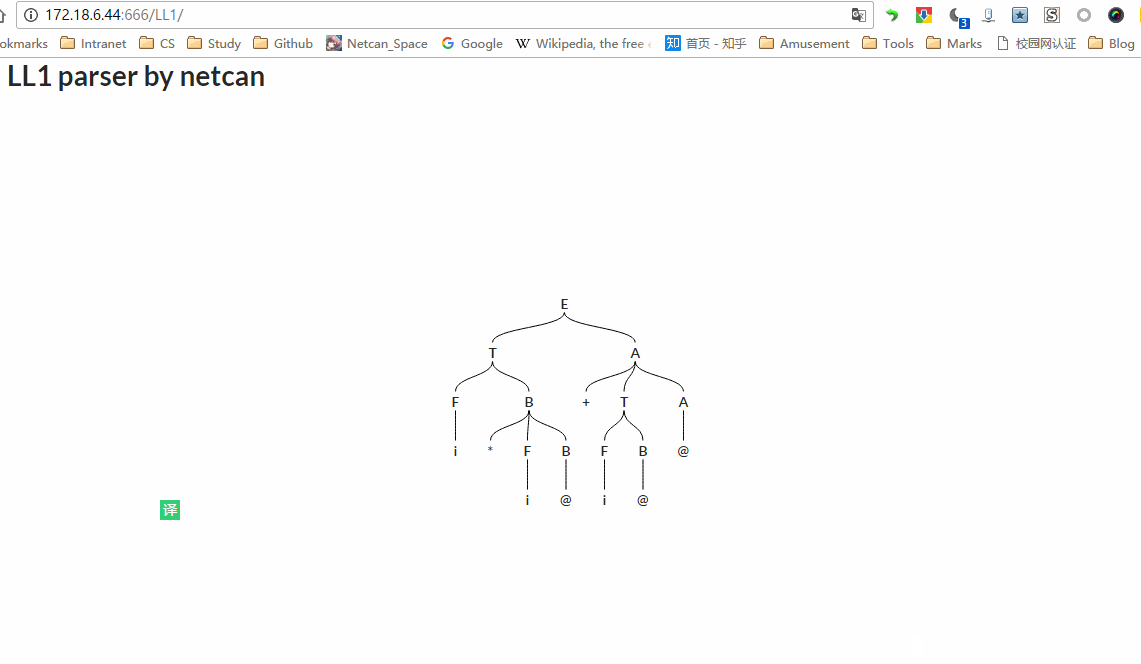
我写这篇博文写了好几天了,描述比较凌乱,建议大家还是看书吧,或者直接看我 程序设计部分 。一定要搞懂
LL(1)文法主要是求
用例子还是比较好说明的,很容易求出各非终结符的
这里给出
也就是说,如果非终结符
用上面的例子来说,匹配
很容易求得
匹配开头为
给出定义,
至于怎么求
连续使用下面的规则,直至每个
- 对于文法的开始符号
,置 #于 中。 - 若
是一个产生式,则把 加至 中; - 若
是一个产生式,或 是一个产生式而 ,则把 加至 中。
第三条规则可以这么理解,因为
所以要求某个非终结符的
预测分析表
求得
对文法的每个产生式,执行下面步骤。
- 对
的每个 终结符 ,将候选式 加入 - 如果
,把 的每个 终结符 (包括 #),把 加入 。
程序设计
代码的核心部分就是求
首先我约定字符 @代表
然后设计一个叫做产生式的类 Prod,它的构造函数接受一个字符串,字符串描述了一个产生式。然后分割字符串,把它的非终结符存入noTerminal 成员中,候选式存入 selection 集合中。
接着设计一个叫 LL1 的类,也就是核心部分了,它提供了求 first、follow、分析表等方法。因为first 集和 follow 集可能会求未知表达式的 first 集和 follow 集,比如说A->B,B->C,欲求first(A),需求first(B),欲求first(B),需求first(C),从而确定了这两种集合求法只能用递归来求,这也是我所能想到的最简单求法,可以参考我代码。
然而现在(2016/10/21)补充下,经过反复调教,first集都重写了 5 次,而 follow 集是 不能用递归 来求的,因为有可能出现这种情况:
求 follow(A) 需要 first(S) 和follow(S),递归求 follow(S) 需要follow(A),然而这样就进入了死递归。所以最后我改写成 5 个循环搞定。
求出了 first 和follow,剩下的就好办了。至于图形界面,和 上次 一样,套了个 php,通过php 传 json 数据到前端,前端输入数据取数据,渲染页面。那颗语法树的画法,通过前序遍历画得。

